
Panduan Lengkap Menggunakan Pandas Di Python Untuk Data Science

Pandas adalah salah satu kerangka kerja python paling populer di kalangan ilmuwan data, analitik data hingga insinyur pembelajaran mesin. Kerangka kerja ini adalah alat penting untuk memuat data, pra-pemrosesan, dan analisis.
Sebelum belajar Panda, Anda harus memahami apa itu data frame? Data Frame adalah struktur data dua dimensi, seperti array 2d, atau mirip dengan tabel dengan baris dan kolom.
Untuk artikel ini, saya menggunakan kumpulan data toko online dummy saya, yang terletak di akun Kaggle dan GitHub saya. Anda dapat mengunduhnya dari keduanya. Juga, saya akan memberi Anda semua buku catatan latihan ini di akun GitHub saya, jadi jangan ragu untuk menggunakannya.
Sebelum memulai artikel, berikut adalah topik yang kami bahas.
Daftar Isi
- Setup
- Memuat Berbagai Format Data
- Prapemrosesan Data
- Manajemen memori
- Analisis data
- Visualisasi data
- Pikiran Terakhir
- Referensi
Jangan ragu untuk memeriksa repo GitHub untuk tutorial ini.
1. Setup
Import
Sebelum melanjutkan untuk mempelajari panda, pertama-tama kita perlu menginstalnya dan mengimpornya. Jika Anda menginstal distribusi Anaconda di mesin lokal Anda atau menggunakan Google Colab maka pandas akan tersedia di sana, jika tidak, Anda mengikuti proses instalasi ini dari situs resmi pandas.
# Importing libraries
import numpy as np
import pandas as pdMengatur Opsi Tampilan
Pengaturan default opsi tampilan panda ada batasan tampilan kolom dan baris. Ketika kita perlu menampilkan lebih banyak baris atau kolom maka kita dapat menggunakan set_option() fungsi untuk menampilkan sejumlah besar baris atau kolom. Untuk fungsi ini, kita dapat mengatur sejumlah nilai baris dan kolom.
# we can set numbers for how many rows and columns will be displayed
pd.set_option('display.min_rows', 10) #default will be 10
pd.set_option('display.max_columns', 20)2. Memuat Berbagai Format Data Ke dalam Bingkai Data Pandas
Pandas adalah alat yang mudah untuk membaca dan menulis berbagai jenis format file. Dengan menggunakan alat ini kita dapat memuat file CSV, Excel, Pdf, JSON, HTML, HDF5, SQL, Google BigQuery, dll dengan mudah.
Berikut adalah beberapa metode, saya akan menunjukkan kepada Anda bagaimana kita dapat membaca dan menulis paling sering menggunakan format file.
Membaca file CSV
CSV (file yang dipisahkan koma) adalah format file yang paling populer. Membaca file ini kami menggunakan fungsi read.csv() sederhana.
# read csv file
df = pd.read_csv('dataset/online_store_customer_data.csv')
df.head(3)
Kita dapat menambahkan beberapa parameter umum untuk mengubah fungsi ini. Jika kita perlu melewatkan beberapa baris pertama dalam bingkai data, maka kita dapat menggunakan argumen kata kunci skiprows. Misalnya, jika kita ingin melewati baris pertama maka kita menggunakan skiprows=2. Demikian pula, jika kita tidak ingin bertahan 2 baris maka kita cukup menggunakan skipfooter=2 . Jika kita tidak ingin memuat header kolom maka kita dapat menggunakan header=None .
# Memuat file csv dengan melewatkan 2 baris pertama tanpa header
df_csv = pd.read_csv('dataset/online_store_customer_data.csv', skiprows=2, header=None)
df_csv.head(3)
Baca file CSV dari URL
Untuk membaca file CSV dari URL, Anda dapat langsung memberikan tautan.
# Read csv file from url
url="https://raw.githubusercontent.com/norochalise/pandas-tutorial-article-2022/main/dataset/online_store_customer_data.csv"
df_url = pd.read_csv(url)
df_url.head(3)Tulis file CSV
Saat Anda ingin menyimpan bingkai data pada file CSV, Anda cukup menggunakan fungsi to.csv(). Anda juga harus memberikan nama file dan itu akan menyimpan file itu.
# saving df_url dataframe to csv file
df_url.to_csv('dataset/csv_from_url.csv')
df_url.to_csv('dataset/demo_text.txt')Baca file teks
Membaca file teks biasa, kita dapat menggunakan fungsi read_csv(). Dalam fungsi ini, Anda harus memberikan nama file .txt.
# read plain text file
df_txt = pd.read_csv("dataset/demo_text.txt")Baca file Excel
Untuk membaca file Excel, kita harus menggunakan read_excel() fungsi dari paket pandas. Jika kita memiliki beberapa nama sheet maka kita dapat meneruskan argumen nama sheet dengan fungsi ini.
# read excel file
df_excel = pd.read_excel('dataset/excel_file.xlsx', sheet_name='Sheet1')
df_excel
Tulis file Excel
Kami dapat menyimpan bingkai data kami ke file excel yang sama dengan file CSV. Anda dapat menggunakan fungsi to_Excel() dengan nama file dan lokasi.
# save dataframe to the excel file
df_url.to_csv('demo.xlsx')3. Pra-pemrosesan data
Preprocessing data adalah proses pembuatan data mentah untuk membersihkan data. Ini adalah bagian terpenting dari ilmu data. Di bagian ini, kita akan mengeksplorasi data terlebih dahulu kemudian menghapus kolom yang tidak diinginkan, menghapus duplikat, menangani data yang hilang, dll. Setelah langkah ini, kita mendapatkan data bersih dari data mentah.
3.1 Penjelajahan Data
Mengambil baris dari bingkai data.
Setelah loading data, hal pertama yang kita lakukan adalah melihat data kita. Untuk tujuan ini kami menggunakan fungsi head() dan tail() . Fungsi kepala akan menampilkan baris pertama dan ekor akan menjadi baris terakhir. Secara default, ini menunjukkan 5 baris. Misalkan kita ingin menampilkan 3 baris pertama dan 6 baris terakhir. Kita bisa melakukannya dengan cara ini.
# display first 3 rows
df.head(3)
# display last 6 rows
df.tail(6)
Mengambil baris sampel dari bingkai data.
Jika kita ingin menampilkan data sampel maka kita dapat menggunakan sample() sebuah fungsi dengan jumlah baris yang diinginkan. Ini akan menunjukkan jumlah baris acak yang diinginkan. Jika kita ingin mengambil 7 sampel, kita harus melewati 7 dalam fungsi sampel(7).
# Display random 7 sample rows
df.sample(7)
Mengambil informasi tentang bingkai data
Untuk menampilkan informasi frame data kita dapat menggunakan metode info(). Ini akan menampilkan tipe data kolom, menghitung total nilai non-null setiap kolom dan ruang memorinya.
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2512 entries, 0 to 2511
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Transaction_date 2512 non-null object
1 Transaction_ID 2512 non-null int64
2 Gender 2484 non-null object
3 Age 2470 non-null float64
4 Marital_status 2512 non-null object
5 State_names 2512 non-null object
6 Segment 2512 non-null object
7 Employees_status 2486 non-null object
8 Payment_method 2512 non-null object
9 Referal 2357 non-null float64
10 Amount_spent 2270 non-null float64
dtypes: float64(3), int64(1), object(7)
memory usage: 216.0+ KBTampilan tipe data setiap kolom kita bisa menggunakan atribut dtypes. Kita dapat menambahkan metode value_counts() di dtypes untuk menampilkan semua tipe data yang menghitung nilai.
# display datatypes
df.dtypesTransaction_date object
Transaction_ID int64
Gender object
Age float64
Marital_status object
State_names object
Segment object
Employees_status object
Payment_method object
Referal float64
Amount_spent float64
dtype: objectdf.dtypes.value_counts()object 7
float64 3
int64 1
dtype: int64Menampilkan jumlah baris dan kolom.
Untuk menampilkan jumlah baris dan kolom kita menggunakan atribut bentuk. Angka pertama dan angka terakhir menunjukkan jumlah baris dan kolom masing-masing.
df.shape(2512, 11)Tampilkan nama kolom dan data
Untuk menampilkan nama kolom dari bingkai data kami, kami menggunakan atribut kolom.
df.columnsIndex(['Transaction_date', 'Transaction_ID', 'Gender', 'Age', 'Marital_status',
'State_names', 'Segment', 'Employees_status', 'Payment_method',
'Referal', 'Amount_spent'],
dtype='object')Jika kita ingin menampilkan data kolom tunggal atau ganda, kita hanya perlu memberikan nama kolom dengan bingkai data. Untuk menampilkan beberapa kolom informasi data, kita perlu melewati daftar nama kolom.
# display Age columns first 3 rows data
df['Age'].head(3)0 19.0
1 49.0
2 63.0
Name: Age, dtype: float64# display first 4 rows of Age, Transaction_date and Gender columns
df[['Age', 'Transaction_date', 'Gender']].head(4)
Mengambil Rentang Baris
Jika kita ingin menampilkan rentang baris tertentu, kita dapat menggunakan slicing. Misalnya, jika kita ingin mendapatkan baris ke-2 hingga ke-6, kita cukup menggunakan df[2:7].
# for display 2nd to 6th rows
df[2:7]
# for display starting to 10th
df[:11]
# for display last two rows
df[-2:]
3.2 Pembersihan Data
Setelah menjelajahi kumpulan data kami mungkin perlu membersihkannya untuk analisis yang lebih baik. Data datang dari berbagai sumber sehingga ada kemungkinan kesalahan dalam beberapa nilai. Di sinilah pembersihan data menjadi sangat penting. Di bagian ini, kami akan menghapus kolom yang tidak diinginkan, mengganti nama kolom, memperbaiki tipe data yang sesuai, dll.
Hapus nama Kolom
Kita dapat menggunakan fungsi drop untuk menghapus kolom yang tidak diinginkan dari bingkai data. Jangan lupa untuk menambahkan inplace = True dan axis=1. Ini akan mengubah nilai dalam bingkai data.
# Drop unwanted columns
df.drop(['Transaction_ID'], axis=1, inplace=True)Ubah nama Kolom
Untuk mengubah nama kolom, kita dapat menggunakan fungsi rename() dengan melewati kamus kolom. Dalam kamus, kami akan memberikan kunci seperti nama kolom lama dan nilai sebagai nama kolom baru yang diinginkan. Sebagai contoh, sekarang kita akan mengubah Transaction_date dan Gender menjadi Date and Sex.
# create new df_col dataframe from df.copy() method.
df_col = df.copy()
# rename columns name
df_col.rename(columns={"Transaction_date": "Date", "Gender": "Sex"}, inplace=True)
df_col.head(3)
Menambahkan kolom baru ke Bingkai Data
Anda dapat menambahkan kolom baru ke bingkai data panda yang ada hanya dengan menetapkan nilai ke nama kolom baru. Misalnya, kode berikut membuat kolom ketiga bernama new_col di bingkai data df_col:
# Add a new_col column which value will be amount_spent * 100
df_col['new_col'] = df_col['Amount_spent'] * 100df_col.head(3)
Nilai string berubah atau diganti
Kita dapat mengganti nilai baru dengan yang lama, dengan metode .loc() dengan bantuan kondisi. Misalnya, sekarang kita mengubah Female to Woman dan Male to Man di kolom Sex.
df_col.head(3)# changing Female to Woman and Male to Man in Sex column.
#first argument in loc function is condition and second one is columns name.
df_col.loc[df_col.Sex == "Female", 'Sex'] = 'Woman'
df_col.loc[df_col.Sex == "Male", 'Sex'] = 'Man'df_col.head(3)
Sekarang nilai kolom Sex diubah Female menjadi Woman dan Male to Man.
Perubahan tipe data
Ketika kita berurusan dengan tipe data yang berbeda, terkadang itu adalah tugas yang membosankan. Jika kita ingin bekerja pada tanggal, kita harus mengubahnya dengan format tanggal yang tepat. Jika tidak, kita mendapatkan masalah. Tugas ini mudah pada panda. Kita dapat menggunakan fungsi astype() untuk mengonversi satu tipe data ke tipe data lainnya.
df_col.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2512 entries, 0 to 2511
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 2512 non-null object
1 Sex 2484 non-null object
2 Age 2470 non-null float64
3 Marital_status 2512 non-null object
4 State_names 2512 non-null object
5 Segment 2512 non-null object
6 Employees_status 2486 non-null object
7 Payment_method 2512 non-null object
8 Referal 2357 non-null float64
9 Amount_spent 2270 non-null float64
10 new_col 2270 non-null float64
dtypes: float64(4), object(7)
memory usage: 216.0+ KBDi kolom Tanggal kami, ini adalah tipe objek jadi sekarang kami akan mengonversinya menjadi tipe tanggal, dan juga kami akan mengonversi kolom Referensi float64 menjadi float32.
# change object type to datefime64 format
df_col['Date'] = df_col['Date'].astype('datetime64[ns]')
# change float64 to float32 of Referal columns
df_col['Referal'] = df_col['Referal'].astype('float32')df_col.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2512 entries, 0 to 2511
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 2512 non-null datetime64[ns]
1 Sex 2484 non-null object
2 Age 2470 non-null float64
3 Marital_status 2512 non-null object
4 State_names 2512 non-null object
5 Segment 2512 non-null object
6 Employees_status 2486 non-null object
7 Payment_method 2512 non-null object
8 Referal 2357 non-null float32
9 Amount_spent 2270 non-null float64
10 new_col 2270 non-null float64
dtypes: datetime64[ns](1), float32(1), float64(3), object(6)
memory usage: 206.2+ KB3.3 Hapus duplikat
Di bagian preprocessing data, kita perlu menghapus entri duplikat. Untuk berbagai jenis alasan terkadang bingkai data kami memiliki beberapa entri duplikat. Menghapus entri duplikat dapat dengan mudah dilakukan dengan bantuan fungsi pandas. Pertama, kami menggunakan fungsi duplikat () untuk mengidentifikasi entri duplikat kemudian kami menggunakan drop_duplicates () untuk menghapusnya.
# Display duplicated entries
df.duplicated().sum()12# duplicate rows dispaly, keep arguments will--- 'first', 'last' and False
duplicate_value = df.duplicated(keep='first')
df.loc[duplicate_value, :]
# dropping ALL duplicate values
df.drop_duplicates(keep = 'first', inplace = True)3.4 Menangani nilai yang hilang
Menangani nilai yang hilang dalam tugas umum di bagian prapemrosesan data. Untuk banyak alasan sebagian besar waktu kita akan menemukan nilai-nilai yang hilang. Tanpa berurusan dengan ini, kita tidak dapat melakukan pembuatan model yang tepat. Untuk bagian ini pertama-tama, kita akan menemukan nilai-nilai yang hilang kemudian kita memutuskan bagaimana menanganinya. Kami dapat menangani ini dengan menghapus kolom atau baris yang terpengaruh atau mengganti nilai yang sesuai di sana.
Tampilkan informasi nilai yang hilang
Untuk menampilkan nilai yang hilang, kita dapat menggunakan fungsi isna(). Menghitung total nilai yang hilang di setiap kolom dalam urutan menaik, kami menggunakan fungsi .sum() dan sort_values(ascending=False).
df.isna().sum().sort_values(ascending=False)Amount_spent 241
Referal 154
Age 42
Gender 28
Employees_status 26
Transaction_date 0
Marital_status 0
State_names 0
Segment 0
Payment_method 0
dtype: int64Hapus baris Nan
Jika kita memiliki nilai Nan yang lebih kecil maka kita dapat menghapus seluruh baris dengan fungsi dropna(). Untuk fungsi ini, kita akan menambahkan nama kolom pada parameter subset.
# df copy to df_copy
df_new = df.copy()#Delete Nan rows of Job Columns
df_new.dropna(subset = ["Employees_status"], inplace=True)Hapus seluruh kolom
Jika kita memiliki sejumlah besar nilai Nan di kolom tertentu, maka menghapus kolom tersebut mungkin merupakan keputusan yang baik daripada menghitung.
df_new.drop(columns=['Amount_spent'], inplace=True)df_new.isna().sum().sort_values(ascending=False)Referal 153
Age 42
Gender 27
Transaction_date 0
Marital_status 0
State_names 0
Segment 0
Employees_status 0
Payment_method 0
dtype: int64Hitung nilai yang hilang
Terkadang jika kita menghapus seluruh kolom itu bukan pendekatan yang tepat. Menghapus kolom dapat mempengaruhi pembuatan model kita karena kita akan kehilangan fitur utama kita. Untuk imputasi, kami memiliki banyak pendekatan, jadi inilah beberapa teknik yang paling populer.
Metode 1—Imputasi nilai tetap seperti 0, 'Tidak Diketahui' atau 'Hilang' dll. Kami memperhitungkan Tidak Diketahui di kolom Gender
df['Gender'].fillna('Unknown', inplace=True)Metode 2—Impute Mean, Median, dan Modus
# Impute Mean in Amount_spent columns
mean_amount_spent = df['Amount_spent'].mean()
df['Amount_spent'].fillna(mean_amount_spent, inplace=True)
#Impute Median in Age column
median_age = df['Age'].median()
df['Age'].fillna(median_age, inplace=True)
# Impute Mode in Employees_status column
mode_emp = df['Employees_status'].mode().iloc[0]
df['Employees_status'].fillna(mode_emp, inplace=True)Metode 3—Iputing forward fill atau backfill dengan ffill dan bfill. Pada ffill missing value imputasi dari nilai baris di atas dan untuk bfill diambil dari nilai baris di bawahnya.
df['Referal'].fillna(method='ffill', inplace=True)df.isna().sum().sum()0Sekarang kita berurusan dengan semua nilai yang hilang dengan metode yang berbeda. Jadi sekarang kami tidak memiliki nilai nol.
4. Manajemen memori
Ketika kami bekerja pada kumpulan data besar, kami mendapatkan satu masalah besar adalah masalah memori. Kami membutuhkan sumber daya yang terlalu besar untuk menangani ini. Tetapi ada beberapa metode di panda untuk mengatasi ini. Berikut adalah beberapa metode atau strategi untuk mengatasi masalah ini dengan bantuan panda.
Ubah tipe data
Dari mengubah satu tipe data ke tipe data lainnya, kita dapat menghemat banyak memori. Salah satu trik populer adalah mengubah objek ke kategori yang akan mengurangi memori bingkai data kita secara drastis.
Pertama, kita akan menyalin bingkai data df sebelumnya ke df_memory dan kita akan menghitung total penggunaan memori dari bingkai data ini menggunakan metode memory_usage(deep=True).
df_memory = df.copy()memory_usage = df_memory.memory_usage(deep=True)
memory_usage_in_mbs = round(np.sum(memory_usage / 1024 ** 2), 3)
print(f" Total memory taking df_memory dataframe is : {memory_usage_in_mbs:.2f} MB ")Total memory taking df_memory dataframe is : 1.15 MBUbah objek ke tipe data kategori
Bingkai data kami berukuran kecil. Yaitu 1,15 MB. Sekarang Kita akan mengubah tipe data objek kita menjadi kategori.
# Object datatype to category convert
df_memory[df_memory.select_dtypes(['object']).columns] = df_memory.select_dtypes(['object']).apply(lambda x: x.astype('category'))# convert object to category
df_memory.info(memory_usage="deep")<class 'pandas.core.frame.DataFrame'>
Int64Index: 2500 entries, 0 to 2511
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Transaction_date 2500 non-null category
1 Gender 2500 non-null category
2 Age 2500 non-null float64
3 Marital_status 2500 non-null category
4 State_names 2500 non-null category
5 Segment 2500 non-null category
6 Employees_status 2500 non-null category
7 Payment_method 2500 non-null category
8 Referal 2500 non-null float64
9 Amount_spent 2500 non-null float64
dtypes: category(7), float64(3)
memory usage: 189.1 KBSekarang berkurang 1,15 megabyte menjadi 216,6 KB. Hampir berkurang 5,5 kali.
Ubah int64 atau float64 menjadi int 32, 16, atau 8
Secara default, panda menyimpan nilai numerik ke int64 atau float64. Yang membutuhkan lebih banyak memori. Jika kita harus menyimpan angka kecil maka kita bisa mengubahnya menjadi 64 menjadi 32, 16, dan seterusnya. Misalnya kolom Referral kita hanya memiliki nilai 0 dan 1 jadi untuk itu kita tidak perlu menyimpan di float64. jadi sekarang kita ubah ke float16.
# Change Referal column datatypes
df_memory['Referal'] = df_memory['Referal'].astype('float32')# convert object to category
df_memory.info(memory_usage="deep")<class 'pandas.core.frame.DataFrame'>
Int64Index: 2500 entries, 0 to 2511
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Transaction_date 2500 non-null category
1 Gender 2500 non-null category
2 Age 2500 non-null float64
3 Marital_status 2500 non-null category
4 State_names 2500 non-null category
5 Segment 2500 non-null category
6 Employees_status 2500 non-null category
7 Payment_method 2500 non-null category
8 Referal 2500 non-null float32
9 Amount_spent 2500 non-null float64
dtypes: category(7), float32(1), float64(2)
memory usage: 179.3 KBSetelah mengubah hanya satu tipe data kolom, kami mengurangi 216 KB menjadi 179 KB.
Catatan: Sebelum mengubah tipe data, pastikan itu konsekuensinya.
5. Analisis Data
5.1. Menghitung Pengukuran statistik dasar
Di bagian analisis data, kita perlu menghitung beberapa pengukuran statistik. Untuk menghitung panda ini memiliki beberapa fungsi yang berguna. Fungsi pertama yang berguna adalah mendeskripsikan() fungsi yang akan menampilkan sebagian besar pengukuran statistik dasar. Untuk fungsi ini, Anda dapat menambahkan .T untuk mengubah tampilan. Ini akan memudahkan untuk melihat ketika ada beberapa kolom.
df.describe().T
Fungsi di atas hanya menampilkan informasi kolom numerik. count menunjukkan berapa banyak nilai yang ada. mean menunjukkan nilai rata-rata setiap kolom. std menunjukkan standar deviasi kolom, yang mengukur jumlah variasi atau dispersi dari sekumpulan nilai. min adalah nilai minimum setiap kolom. 25%, 50%, dan 75% menunjukkan nilai total terletak pada kelompok itu, dan akhirnya max menunjukkan nilai maksimum dari kolom itu.
Kita sudah tahu kode di atas hanya akan menampilkan kolom numerik informasi statistik dasar. untuk kolom objek atau kategori kita dapat menggunakan deskripsi(include=object) .
df.describe(include=object).T
Informasi di atas, count menunjukkan berapa banyak nilai yang ada. unik adalah berapa banyak nilai yang unik di kolom itu. Bagian atas adalah jumlah nilai tertinggi yang terletak dalam kategori itu. freq menunjukkan berapa banyak nilai yang sering terletak pada nilai teratas itu.
Kita dapat menghitung mean, median, mode, nilai maksimum, nilai minimum dari masing-masing kolom, kita cukup menggunakan fungsi-fungsi ini.
# Calculate Mean
mean = df['Age'].mean()
# Calculate Median
median = df['Age'].median()
#Calculate Mode
mode = df['Age'].mode().iloc[0]
# Calculate standard deviation
std = df['Age'].std()
# Calculate Minimum values
minimum = df['Age'].min()
# Calculate Maximum values
maximum = df.Age.max()
print(f" Mean of Age : {mean}")
print(f" Median of Age : {median}")
print(f" Mode of Age : {mode}")
print(f" Standard deviation of Age : {std:.2f}")
print(f" Maximum of Age : {maximum}")
print(f" Menimum of Age : {minimum}")Mean of Age : 46.636
Median of Age : 47.0
Mode of Age : 47.0
Standard deviation of Age : 18.02
Maximum of Age : 78.0
Menimum of Age : 15.0Di panda, kita dapat menampilkan korelasi kolom numerik yang berbeda. Untuk ini, kita dapat menggunakan fungsi .corr().
# calculate correlation
df.corr()
5.2 Fungsi bawaan dasar untuk analisis data
Di panda, ada begitu banyak fungsi dasar yang berguna yang tersedia untuk analisis data. Di bagian ini, kami mengeksplorasi beberapa fungsi yang paling sering digunakan.
Jumlah nilai unik di kolom kategori
Untuk menampilkan jumlah semua nilai unik, kami menggunakan nunique() fungsi nama kolom yang diinginkan. Misalnya, tampilkan nilai unik total di kolom State_names kita menggunakan fungsi ini:
# for display how many unique values are there in State_names column
df['State_names'].nunique()50Menampilkan semua nilai unik
Untuk menampilkan semua nilai unik kami menggunakan fungsi unique() dengan nama kolom yang diinginkan.
# for display uniqe values of State_names column
df['State_names'].unique()array(['Kansas', 'Illinois', 'New Mexico', 'Virginia', 'Connecticut',
'Hawaii', 'Florida', 'Vermont', 'California', 'Colorado', 'Iowa',
'South Carolina', 'New York', 'Maine', 'Maryland', 'Missouri',
'North Dakota', 'Ohio', 'Nebraska', 'Montana', 'Indiana',
'Wisconsin', 'Alabama', 'Arkansas', 'Pennsylvania',
'New Hampshire', 'Washington', 'Texas', 'Kentucky',
'Massachusetts', 'Wyoming', 'Louisiana', 'North Carolina',
'Rhode Island', 'West Virginia', 'Tennessee', 'Oregon', 'Alaska',
'Oklahoma', 'Nevada', 'New Jersey', 'Michigan', 'Utah', 'Arizona',
'South Dakota', 'Georgia', 'Idaho', 'Mississippi', 'Minnesota',
'Delaware'], dtype=object)Hitungan nilai unik
Untuk menampilkan jumlah nilai unik, kami menggunakan metode value_counts(). Fungsi ini akan menampilkan nilai unik dengan nomor dari setiap nilai yang muncul. Sebagai contoh, jika kita ingin mengetahui berapa banyak nilai unik kolom Gender dengan nilai frekuensi jumlah maka kita menggunakan metode di bawah ini.
df['Gender'].value_counts()Female 1351
Male 1121
Unknown 28
Name: Gender, dtype: int64Jika kita ingin menunjukkan dengan persentase kemunculan daripada angka, kita menggunakan argumen normalize=True dalam fungsi value_counts()
# Calculate percentage of each category
df['Gender'].value_counts(normalize=True)Female 0.5404
Male 0.4484
Unknown 0.0112
Name: Gender, dtype: float64df['State_names'].value_counts().sort_values(ascending = False).head(20)Illinois 67
Georgia 64
Massachusetts 63
Maine 62
Kentucky 59
Minnesota 59
Delaware 56
Missouri 56
New York 55
New Mexico 55
Arkansas 55
California 55
Arizona 55
Nevada 55
Vermont 54
New Jersey 53
Oregon 53
Florida 53
West Virginia 53
Washington 52
Name: State_names, dtype: int64>Urutkan nilai
Jika kita ingin mengurutkan bingkai data berdasarkan kolom tertentu, kita perlu menggunakan metode sort_values(). Kita dapat menggunakan pengurutan berdasarkan urutan menaik atau menurun. Secara default, ini dalam urutan menaik. Jika kita ingin menggunakan urutan menurun maka kita hanya perlu meneruskan argumen ascending=False di sort_values() fungsi.
# Sort Values by State_names
df.sort_values(by=['State_names']).head(3)
Untuk menyortir bingkai data kami berdasarkan Amount_spent dengan urutan menaik:
# Sort Values Amount_spent with ascending order
df.sort_values(by=['Amount_spent']).head(3)
Untuk menyortir bingkai data kami berdasarkan Amount_spent dengan urutan menurun:
# Sort Values Amount_spent with descending order
df.sort_values(by=['Amount_spent'], ascending=False).head(3)
Atau, Kita dapat menggunakan fungsi nlargest() dan nsmallest() untuk menampilkan nilai terbesar dan terkecil dengan angka yang diinginkan. misalnya, Jika kita ingin menampilkan 4 baris Amount_spent terbesar maka kita menggunakan ini:
# nlargest
df.nlargest(4, 'Amount_spent').head(10) # first argument is how many rows you want to disply and second one is columns name
Untuk 3 baris Amount_spent terkecilZ
# nsmallest
df.nsmallest(3, 'Age').head(10)
Kueri bersyarat pada Data
Jika kita ingin menerapkan satu kondisi maka pertama-tama kita akan memberikan satu kondisi kemudian kita meneruskan pada bingkai data. Misalnya, jika kami ingin menampilkan semua baris di mana Payment_method adalah PayPal, maka kami menggunakan ini:
# filtering - Only show Paypal users
condition = df['Payment_method'] == 'PayPal'
df[condition].head(4)
Kami dapat menerapkan beberapa kueri bersyarat seperti sebelumnya. Misalnya, jika kita ingin menampilkan semua wanita yang sudah menikah yang tinggal di New York maka kita menggunakan yang berikut ini:
# first create 3 condition
female_person = df['Gender'] == 'Female'
married_person = df['Marital_status'] == 'Married'
loc_newyork = df['State_names'] == 'New York'
# we passing condition on our dataframe
df[female_person & married_person & loc_newyork].head(4)
5.3 Meringkas atau mengelompokkan data
Kelompokkan menurut
Di Pandas group by function lebih populer di bagian analisis data. Ini memungkinkan untuk membagi dan mengelompokkan data, menerapkan fungsi, dan menggabungkan hasilnya. Kita dapat memahami fungsi ini dan menggunakannya dengan contoh di bawah ini:
Pengelompokan berdasarkan satu kolom: Misalnya, jika kita ingin mencari nilai maksimum Age dan Amount_spent by Gender maka kita dapat menggunakan ini:
df[['Age', 'Amount_spent']].groupby(df['Gender']).max()
Untuk mencari nilai mean, count, dan max dari Age dan Amount_spent by Gender maka kita dapat menggunakan fungsi agg() dengan groupby() .
# Group by one columns
state_gender_res = df[['Age','Gender','Amount_spent']].groupby(['Gender']).agg(['count', 'mean', 'max'])
state_gender_res
Pengelompokan berdasarkan beberapa kolom: Untuk menemukan jumlah total, nilai maksimum dan minimum Amount_spent by State_names, Gender, dan Payment_method maka kita dapat meneruskan nama kolom ini di bawah fungsi groupby() dan menambahkan .agg() dengan argumen count, mean, max.
#Group By multiple columns
state_gender_res = df[['State_names','Gender','Payment_method','Amount_spent']].groupby([ 'State_names','Gender', 'Payment_method']).agg(['count', 'min', 'max'])
state_gender_res.head(12)
Tabulasi Silang (Cross tab)
Tabulasi silang (juga disebut sebagai tab silang) adalah metode untuk menganalisis secara kuantitatif hubungan antara beberapa variabel. Juga dikenal sebagai tabel kontingensi. Ini akan membantu untuk memahami korelasi antara variabel yang berbeda. Untuk membuat tabel ini, panda memiliki fungsi bawaan crosstab().
Untuk membuat tab silang sederhana antara kolom Maritatal_status dan Payment_method, kita cukup menggunakan tab silang() dengan kedua nama kolom.
pd.crosstab(df.Marital_status, df.Payment_method)
Kami dapat menyertakan subtotal dengan parameter margin:
pd.crosstab(df.Marital_status, df.Payment_method, margins=True, margins_name="Total")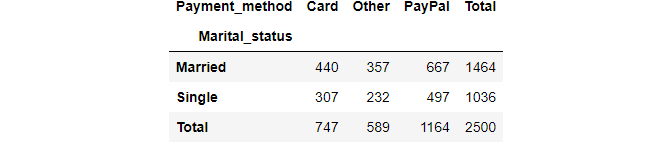
Jika Kami ingin tampilan dengan persentase dari normalize=True parameter help
pd.crosstab(df.Marital_status, df.Payment_method, normalize=True, margins=True, margins_name="Total")
Dalam fitur tab silang ini, kita dapat melewatkan beberapa nama kolom untuk mengelompokkan dan menganalisis data. Sebagai contoh, jika kita ingin melihat bagaimana Payment_method dan Employee_status didistribusikan oleh Marital_status maka kita akan melewatkan nama-nama kolom ini dalam fungsi crosstab() dan akan ditampilkan di bawah ini.
pd.crosstab(df.Marital_status, [df.Payment_method, df.Employees_status])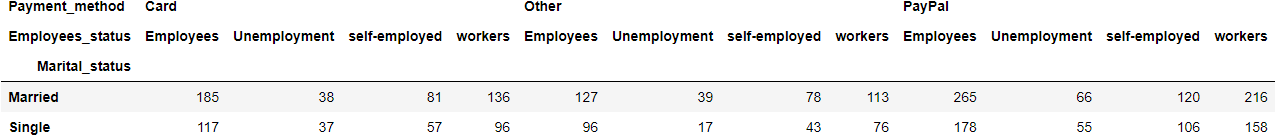
6. Visualisasi Data
Visualisasi adalah kunci untuk analisis data. Paket python paling populer untuk visualisasi adalah matplotlib dan seaborn tetapi terkadang panda akan berguna untuk Anda. Panda juga menyediakan beberapa plot visualisasi dengan mudah. Untuk bagian analisis dasar, akan mudah digunakan. Untuk bagian ini, kami menjelajahi beberapa jenis plot yang berbeda menggunakan panda. Berikut plotnya.
6.1 Plot garis
Plot garis adalah yang paling sederhana dari semua plot grafis. Plot garis digunakan untuk mengikuti perubahan sepanjang waktu dan menampilkan informasi sebagai rangkaian. Bagan garis ideal untuk membandingkan beberapa variabel dan memvisualisasikan tren untuk variabel tunggal dan ganda.
Untuk membuat plot garis di panda, kami menggunakan .plot() nama dua kolom untuk argumennya. Misalnya, kami membuat plot garis dari satu kumpulan data dummy.
dict_line = {
'year': [2016, 2017, 2018, 2019, 2020, 2021],
'price': [200, 250, 260, 220, 280, 300]
}
df_line = pd.DataFrame(dict_line)# use plot() method on the dataframe
df_line.plot('year', 'price');
Bagan garis di atas menunjukkan harga selama waktu yang berbeda. Ini menunjukkan seperti tren harga.
6.2 Petak Diagram
Plot batang juga dikenal sebagai diagram batang yang menunjukkan nilai kuantitatif atau kualitatif untuk item kategori yang berbeda. Dalam sebuah bar, data plot direpresentasikan dalam bentuk bar. Panjang atau tinggi batang digunakan untuk mewakili nilai kuantitatif untuk setiap item. Plot batang dapat diplot secara horizontal atau vertikal. Untuk membuat plot ini lihat di bawah.
Untuk diagram horizontal:
df['Employees_status'].value_counts().plot(kind='bar');
Untuk diagram vertikal:
6.3 Plot pai
Plot pie juga dikenal sebagai diagram lingkaran. Pie plot adalah grafik melingkar yang mewakili nilai total dengan komponen-komponennya. Luas lingkaran mewakili nilai total dan berbagai sektor lingkaran mewakili bagian-bagian yang berbeda. Dalam plot ini, data dinyatakan sebagai persentase. Setiap komponen dinyatakan sebagai persentase dari nilai total.
Di panda untuk membuat plot pai. Kami menggunakan fungsi kind=pie in plot() di kolom atau seri bingkai data.
df['Segment'].value_counts().plot(
kind='pie');
6.4 Petak Kotak
Plot kotak juga dikenal sebagai plot kotak dan kumis. Plot ini digunakan untuk menunjukkan distribusi suatu variabel berdasarkan kuartilnya. Plot kotak menampilkan ringkasan lima angka dari sekumpulan data. Ringkasan lima angka adalah minimum, kuartil pertama, median, kuartil ketiga, dan maksimum. Ini juga akan populer untuk mengidentifikasi outlier.
Kita dapat memplot ini dengan satu kolom atau beberapa kolom. Untuk beberapa kolom, kita perlu memberikan nama kolom dalam variabel y sebagai daftar.
df.plot(y=['Amount_spent'], kind='box');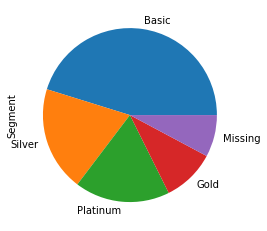

Dalam plot kotak, kita dapat memplot distribusi variabel kategori terhadap variabel numerik dan membandingkannya. Mari kita plot dengan kolom Employee_status dan Amount_spent dengan metode pandas boxplot():
import matplotlib.pyplot as plt
np.warnings.filterwarnings('ignore', category=np.VisibleDeprecationWarning)
fig, ax = plt.subplots(figsize=(6,6))
df.boxplot(by ='Employees_status', column =['Amount_spent'],ax=ax, grid = False);
6.5 Histogram
Histogram menunjukkan frekuensi dan distribusi pengukuran kuantitatif di seluruh nilai yang dikelompokkan untuk item data. Ini biasanya digunakan dalam statistik untuk menunjukkan berapa banyak jenis variabel tertentu yang terjadi dalam rentang atau ember tertentu. Di bawah ini kami akan memplot histogram untuk melihat distribusi Usia.
df.plot(
y='Age',
kind='hist',
bins=10
);
6.6 plot KDE
Plot estimasi kepadatan kernel (KDE) adalah metode untuk memvisualisasikan distribusi pengamatan dalam kumpulan data, analog dengan histogram. KDE mewakili data menggunakan kurva kepadatan probabilitas kontinu dalam satu atau lebih dimensi.
df.plot(
y='Age',
xlim=(0, 100),
kind='kde'
);
6.7 Plot pencar
Sebuah plot pencar digunakan untuk mengamati dan menunjukkan hubungan antara dua variabel kuantitatif untuk item kategori yang berbeda. Setiap anggota kumpulan data diplot sebagai titik yang koordinat xy terkait dengan nilainya untuk dua variabel. Di bawah ini kita akan membuat plot sebar untuk menampilkan hubungan antara kolom Age dan Amount_spent.
df.plot(
x='Age',
y='Amount_spent',
kind='scatter'
);
7. Pikiran Akhir
Dalam artikel ini, kita mengetahui bagaimana panda dapat digunakan untuk membaca, memproses, menganalisis, dan memvisualisasikan data. Ini juga dapat digunakan untuk manajemen memori untuk komputasi cepat dengan sumber daya yang lebih sedikit. Motif utama artikel ini adalah untuk membantu orang-orang yang ingin belajar panda untuk analisis data.
Apakah Anda memiliki pertanyaan atau bantuan terkait dengan artikel ini, jangan ragu untuk menghubungi saya di LinkedIn. Jika Anda merasa artikel ini bermanfaat, silakan ikuti saya untuk pembelajaran lebih lanjut. Saran dan umpan balik Anda selalu diterima. Terima kasih telah membaca artikel saya. Selamat belajar.
Jangan ragu untuk memeriksa repo GitHub untuk tutorial ini.
8. Referensi
- Panduan pengguna Pandas
- Pandas 1.x Buku Masak
- Lokakarya Penanganan Data
- Python untuk Analisis Data
- Analisis Data dengan Python: Zero to Pandas—Jovian YouTube Channel
- Praktik terbaik dengan panda—Saluran YouTube Data School
- Tutorial Pandas—Saluran YouTube Corey Schafer
- Panda Crosstab Dijelaskan
Artikel Terkait Lainnya :
- Mari Kita Kenalan Dengan Teknologi PyScript
- Cara Mendefinisikan Metode NonPublic Di Class Python
- Saatnya Mengucapkan Selamat Tinggal Pada Lybrary Python Yang Sudah Usang Ini
- Menentukan Bahasa Yang Menjanjikan Untuk Web Developers (JavaScript Atau Python)
- Cara Menghasilkan Uang dengan Scraping Web Menggunakan Python